Grep-käsu kasutamine Linuxis

Linux grep käsk on stringi ja mustriga sobitamise utiliit, mis kuvab mitme faili sobivad read. See töötab ka teiste käskude torustikulise väljundiga. Me näitame teile, kuidas.
Grepi lugu
The grep käsk on Linuxi ja Unixi ringkondades kuulus kolmel põhjusel. Esiteks on see tohutult kasulik. Teiseks võib valikuvõimalus olla tohutu. Kolmandaks kirjutati see üleöö konkreetse vajaduse rahuldamiseks. Kaks esimest on paugu peal; kolmas on kergelt väljas.
Ken Thompson oli regulaaravaldise otsimisvõimalused rakendusest toim redaktor (hääldatakse ee-dee) ja lõi tekstifailide otsimiseks väikese programmi enda tarbeks. Tema osakonnajuhataja Bell Labsis Doug Mcilroy pöördus Thompsoni poole ja kirjeldas probleemi, millega üks tema kolleeg Lee McMahon silmitsi seisis.
McMahon üritas tekstianalüüsi abil tuvastada föderalistlike dokumentide autoreid. Ta vajas tööriista, mis otsiks fraase ja stringe tekstifailidest. Thompson veetis sellel õhtul umbes tunni, muutes oma tööriista üldiseks utiliidiks, mida teised saaksid kasutada, ja nimetas selle ümber grep. Ta võttis selle nime toim käsurida g / re / lk , mis tõlgitakse kui "globaalse regulaaravaldise otsimine".
Saate vaadata, kuidas Thompson rääkis Brian Kernighaniga sünnist grep.
Lihtsad otsingud grepiga
Failis stringi otsimiseks edastage käsureal otsingutermin ja failinimi:

Kuvatakse sobivad read. Sel juhul on see üks rida. Sobiv tekst on esile tõstetud. Seda seetõttu, et enamikul jaotustel grep on varjunimega:
varjunimi grep = "grep --color = auto"
Vaatame tulemusi, kus on mitu rida, mis sobivad. Otsime rakenduse logifailist sõna „keskmine”. Kuna me ei mäleta, kas see sõna on logifailis väiketähtedega, kasutame seda -i (ignoreeri juhtumit) variant:
grep -i Keskmine geek-1.log

Kuvatakse iga sobiv rida, kusjuures vastav tekst on igas esile tõstetud.

Mittesobivaid ridu saame kuvada -v (invertsobivus) abil.
grep -v Mem geek-1.log

Esiletõstmist pole, sest need on mittesobivad read.

Me võime põhjustada grep täiesti vait olla. Tulemus edastatakse kestale tagastusväärtusena grep. Nulli tulemus tähendab stringi oli leitud ja ühe tulemus tähendab seda ei olnud leitud. Tagastuskoodi saame kontrollida, kasutades $? eriparameetrid:
grep -q keskmine geek-1.log
kaja $?
grep -q howtogeek geek-1.log
kaja $?

Rekursiivsed otsingud grepiga
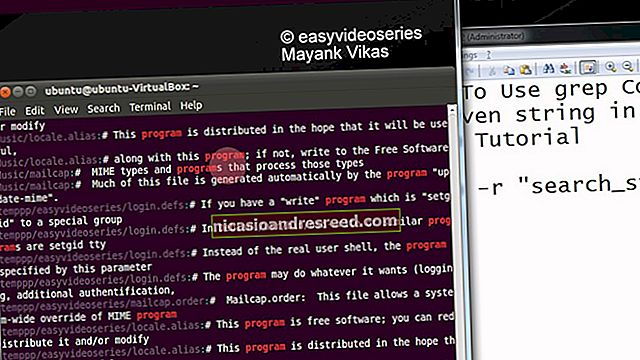
Pesastatud kataloogide ja alamkataloogide otsimiseks kasutage valikut -r (rekursiivne). Pange tähele, et te ei anna käsureal failinime, vaid peate sisestama tee. Siin otsime praegusest kataloogist "." ja kõik alamkataloogid:
grep -r -i memfree.

Väljund sisaldab iga sobiva rea kataloogi ja failinime.

Me saame tehagrep järgige sümboolseid linke, kasutades -R (rekursiivne dereferents) variant. Selles kataloogis on sümboolne link nimega logid-kaust. See osutab / home / dave / logid.
ls -l logib kausta

Kordame oma viimast otsingut-R (rekursiivne dereferents) variant:
grep -R -i memfree.

Järgitakse sümboolset linki ja otsitakse kataloogi, millele see osutab grep ka.

Tervete sõnade otsimine
Algselt, grep sobib reaga, kui otsitav sihtmärk ilmub kusagil sellel real, ka teise stringi sees. Vaadake seda näidet. Otsime sõna "tasuta".
grep -i tasuta geek-1.log

Tulemused on read, milles on string "vaba", kuid need ei ole eraldi sõnad. Need kuuluvad stringi „MemFree”.

Sundima grep Ainult eraldi sõnade sobitamiseks kasutage -w (sõna regexp) variant.
grep -w -i tasuta geek-1.log
kaja $?

Seekord pole tulemusi, kuna otsinguterminit "tasuta" ei kuvata failis eraldi sõnana.
Mitme otsingutermini kasutamine
The -E (laiendatud regexp) valik võimaldab teil otsida mitut sõna. ( -E Valik asendab iganenud egrep versioon grep.)
See käsk otsib kahte otsinguterminit „keskmine” ja „memfree”.
grep -E -w -i "keskmine | memfree" geek-1.log

Kõigi otsinguterminite jaoks kuvatakse kõik sobivad read.

Samuti saate otsida mitut mõistet, mis ei pruugi olla terved sõnad, kuid need võivad olla ka terved sõnad.
The -e (mustrid) valik võimaldab käsureal kasutada mitut otsinguterminit. Otsingu mustri loomiseks kasutame tavalise avaldise sulgude funktsiooni. See ütleb grep sobitada ükskõik millises sulgudes sisalduvast märgist „[]”. See tähendab grep otsingu ajal sobib kas “kB” või “KB”.

Mõlemad stringid on omavahel sobitatud ja tegelikult sisaldavad mõned read mõlemat stringi.

Liinide sobitamine täpselt
The-x (line regexp) sobib ainult joontega, kus kogu rida vastab otsinguterminile. Otsime kuupäeva- ja ajatemplit, mis teadaolevalt ilmub logifailis ainult üks kord:
grep -x "20. jaanuar - 06 15:24:35" geek-1.log

Leitakse ja kuvatakse üks sobiv rida.
Selle vastand näitab ainult jooni, mis ära tee matš. See võib olla kasulik konfiguratsioonifailide vaatamisel. Kommentaarid on toredad, kuid mõnikord on nende kõigi seas tegelikke seadeid raske märgata. Siin on / etc / sudoers fail:

Saame tõhusalt välja filtreerida sellised kommentaariread:
sudo grep -v "#" / etc / sudoers

Seda on palju lihtsam sõeluda.
Kuvatakse ainult sobivat teksti
Võib juhtuda, et te ei soovi näha tervet vastavat rida, vaid ainult sobivat teksti. The -o (ainult sobitamine) variant teeb seda.
grep -o MemFree geek-1.log

Kuvatakse ainult kogu otsingureale vastava teksti kuvamine kogu vaste rea asemel.

Grepiga loendamine
grep ei puuduta ainult teksti, vaid võib pakkuda ka arvulist teavet. Me saame teha grep loe meile erinevatel viisidel. Kui tahame teada, mitu korda otsingutermin failis ilmub, saame kasutada -c (loenda) variant.
grep -c keskmine geek-1.log

grep teatab, et otsingutermin ilmub selles failis 240 korda.
Saate teha grep kuvage iga sobiva rea rea number, kasutades nuppu -n (rea number) valik.
grep -n Jan geek-1.log

Iga sobiva rea rea number kuvatakse rea alguses.

Kuvatavate tulemuste arvu vähendamiseks kasutage nuppu -m (max arv) variant. Piirame väljundi viie sobiva reaga:
grep -m5 -n Jan geek-1.log

Konteksti lisamine
Tihti on kasulik iga sobiva rea jaoks näha mõnda täiendavat rida - võib-olla mittesobivaid ridu. see võib aidata eristada, millised sobitatud read on need, mis teid huvitavad.
Mõne rea kuvamiseks pärast sobivat joont kasutage -A (pärast konteksti) valikut. Selles näites küsime kolme rida:
grep -A 3 -x "20. jaanuar-06 15:24:35" geek-1.log

Mõne rea leidmiseks enne sobivat joont kasutage klahvi -B (kontekst enne) variant.
grep -B 3 -x "20. jaanuar-06 15:24:35" geek-1.log

Ja et lisada read enne ja pärast sobitamisjoont, kasutage -C (kontekst) variant.
grep -C 3 -x "20. jaanuar-06 15:24:35" geek-1.log

Kuvatakse sobivad failid
Otsinguterminit sisaldavate failide nimede nägemiseks kasutage nuppu -L (vastega failid) valik. Et teada saada, millised C lähtekoodi failid sisaldavad viiteid failile sl.h päisefail, kasutage seda käsku:
grep -l "sl.h" * .c

Loendis on failinimed, mitte vastavad read.

Ja loomulikult võime otsida faile, mis ei sisalda otsingutermini. The -L (failid ilma vasteta) teeb seda.
grep -L "sl.h" * .c

Liinide algus ja lõpp
Me võime sundida grep kuvada ainult vasteid, mis on kas rea alguses või lõpus. Regulaaravaldise operaator “^” vastab rea algusele. Praktiliselt kõik logifaili read sisaldavad tühikuid, kuid otsime ridu, mille esimese märgina on tühik:
grep "^" geek-1.log

Kuvatakse read, mille esimese märgina on tühik - rea alguses.

Rea lõppu sobitamiseks kasutage regulaaravaldise operaatorit $. Otsime ridu, mis lõpevad tähega „00”.
grep "00 $" geek-1.log

Ekraanil kuvatakse read, mille viimasteks märkideks on “00”.

Grepiga torude kasutamine
Muidugi saate sisestada toru grep , torustage väljund grep teise programmi ja on grep pesitses keset toruketti.
Oletame, et soovime näha kõiki C-lähtekoodi failides stringi „ExtractParameters” esinemisi. Me teame, et neid tuleb üsna vähe, nii et me sisestame väljundi vähem:
grep "ExtractParameters" * .c | vähem

Väljund on esitatud vähem.

See võimaldab teil sirvida failide loendit ja seda kasutada vähem otsimisvõimalus.
Kui me torustame väljundi grep sisse tualett ja kasutage -L (read) valiku korral võime lugeda lähtekoodi failide ridade arvu, mis sisaldavad "ExtractParameters". (Selle saavutaksime grep-c (count) variant, kuid see on hea viis demonstreerida grep.)
grep "ExtractParameters" * .c | wc -l

Järgmise käsuga edastame väljundi ls sisse grep ja väljundi torustik grep sisse sorteerida . Loetleme failid praegusesse kataloogi, valime need, milles on string „Aug”, ja sorteerime need faili suuruse järgi:
ls -l | grep "aug" | sort + 4n

Jaotame selle:
- ls -l: Koostage failide pika vorminguga loend
ls. - grep "august": Valige read reast
lsloendis on aug. Pange tähele, et see leiaks ka failid, mille nimes on „Aug”. - sort + 4n: Sorteerige väljund grepist neljandas veerus (failisuurus).
Saame järjestatud loendi kõigist augustis muudetud failidest (sõltumata aastast) failide suuruse kasvavas järjekorras.
SEOTUD:Torude kasutamine Linuxis
grep: vähem käsku, rohkem liitlast
grep on suurepärane vahend, mis teie käsutuses on. See pärineb aastast 1974 ja on endiselt tugev, sest me vajame seda, mida ta teeb, ja miski ei tee seda paremini.
Sidumine grep mõne regulaaravaldisega viib fu selle tõesti järgmisele tasandile.
SEOTUD:Kuidas kasutada tavalisi väljendeid paremaks otsimiseks ja aja kokkuhoiuks